通义
语音
Qwen_Audio
Qwen-Audio 是阿里云研发的大规模音频语言模型(Large Audio Language Model)。Qwen-Audio 可以以多种音频 (包括说话人语音、自然音、音乐、歌声)和文本作为输入,并以文本作为输出。
0元/小时
v1.0
Qwen-Audio-chat WebDemo 部署
Qwen-Audio 介绍
Qwen-Audio 是阿里云研发的大规模音频语言模型(Large Audio Language Model)。Qwen-Audio 可以以多种音频 (包括说话人语音、自然音、音乐、歌声)和文本作为输入,并以文本作为输出。
镜像快速使用教程
1. 待实例初始化完成后,在控制台-应用中打开”JupyterLab“
2. 进入Jupyter后,新建一个终端Terminal,输入以下指令
streamlit run /Qwen_Audio/compshared-tmp/chatBot.py --server.port 5910
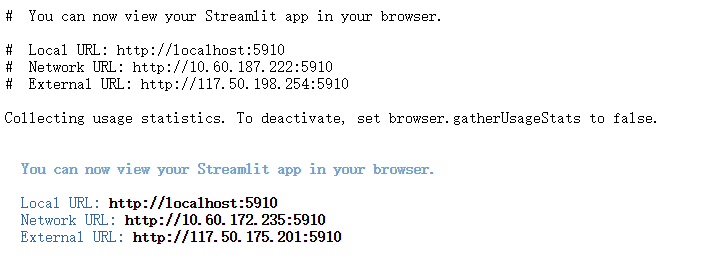
#Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
# You can now view your Streamlit app in your browser.
# Local URL: http://localhost:5910
# Network URL: http://10.60.187.222:5910
# External URL: http://117.50.198.254:5910
3. 点击这个外部链接http://117.50.198.254:5910让软件初始化激活 ,然后等待模型加载完毕后,在浏览器中打开链接 http://(外部IP):11434,即可看到聊天界面
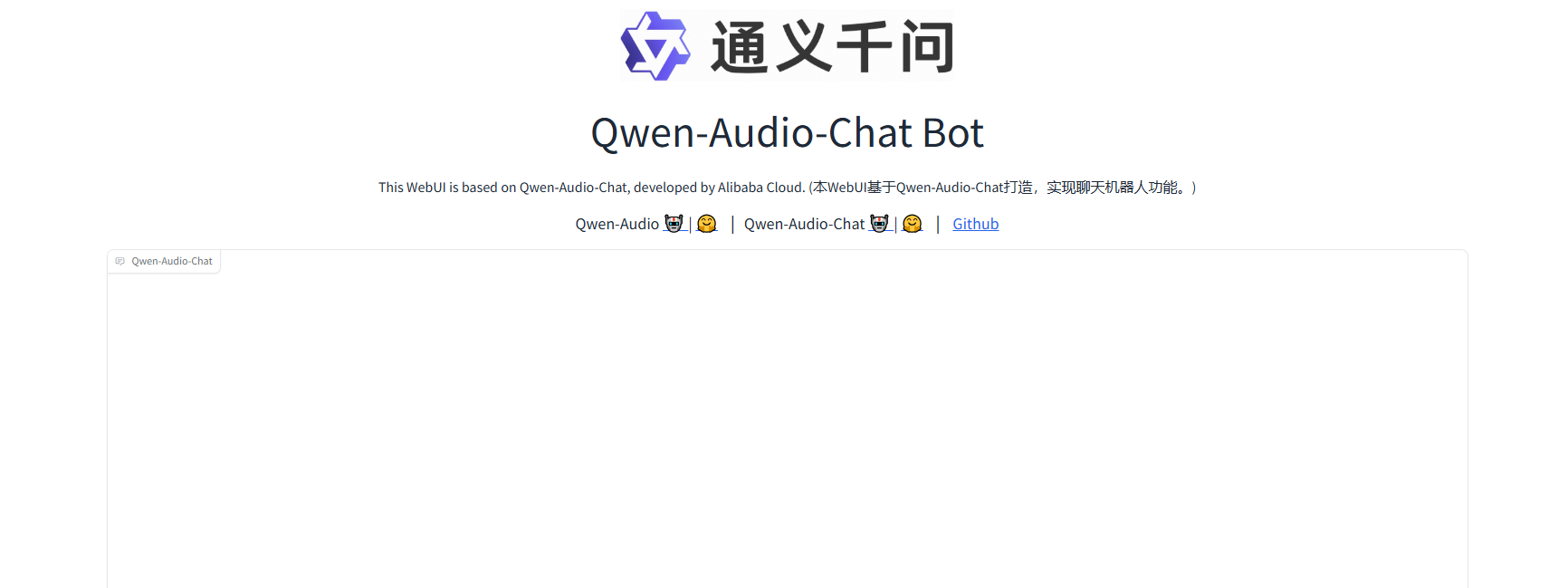
成功进入web界面如下图所示
环境准备
打开终端开始环境配置、模型下载和运行演示。 pip换源和安装依赖包
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.9.5
pip install accelerate
pip install tiktoken
pip install einops
pip install transformers_stream_generator==0.0.4
pip install scipy
pip install torchvision
pip install pillow
pip install tensorboard
pip install matplotlib
pip install transformers==4.32.0
pip install gradio==3.39.0
pip install nest_asyncio
模型下载
使用 modelscope 中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在 /Qwen_Audio/compshared-tmp 路径下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /Qwen_Audio/compshared-tmp/download.py 执行下载,模型大小为 20 GB,下载模型大概需要10~20分钟
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
from modelscope import GenerationConfig
model_dir = snapshot_download(qwen/Qwen-Audio-Chat, cache_dir=/Qwen_Audio/compshared-tmp, revision=master)
代码准备
在/Qwen_Audio/compshared-tmpp路径下新建 chatBot.py 文件并在其中输入以下内容,粘贴代码后记得保存文件。下面的代码有很详细的注释,大家如有不理解的地方,欢迎提出issue。
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
A simple web interactive chat demo based on gradio.
from argparse import ArgumentParser
from pathlib import Path
import copy
import gradio as gr
import os
import re
import secrets
import tempfile
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
from pydub import AudioSegment
# DEFAULT_CKPT_PATH = Qwen/Qwen-Audio-Chat
DEFAULT_CKPT_PATH = /Qwen_Audio/compshared-tmp/qwen/Qwen-Audio-Chat
def _get_args():
parser = ArgumentParser()
parser.add_argument(-c, --checkpoint-path, type=str, default=DEFAULT_CKPT_PATH,
help=Checkpoint name or path, default to %(default)r)
parser.add_argument(--cpu-only, action=store_true, help=Run demo with CPU only)
parser.add_argument(--share, action=store_true, default=False,
help=Create a publicly shareable link for the interface.)
parser.add_argument(--inbrowser, action=store_true, default=False,
help=Automatically launch the interface in a new tab on the default browser.)
parser.add_argument(--server-port, type=int, default=11434,
help=Demo server port.)
parser.add_argument(--server-name, type=str, default=0.0.0.,
help=Demo server name.)
args = parser.parse_args()
return args
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
if args.cpu_only:
device_map = cpu
else:
device_map = cuda
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map=device_map,
trust_remote_code=True,
resume_download=True,
).eval()
model.generation_config = GenerationConfig.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
return model, tokenizer
def _parse_text(text):
lines = text.split(\n)
lines = [line for line in lines if line != ]
count = 0
for i, line in enumerate(lines):
if ``` in line:
count += 1
items = line.split(`)
if count % 2 == 1:
lines[i] = f<pre><code class=language-{items[-1]}>
else:
lines[i] = f<br></code></pre>
else:
if i > 0:
if count % 2 == 1:
line = line.replace(`, r\`)
line = line.replace(<, <)
line = line.replace(>, >)
line = line.replace( , )
line = line.replace(*, *)
line = line.replace(_, _)
line = line.replace(-, -)
line = line.replace(., .)
line = line.replace(!, !)
line = line.replace((, ()
line = line.replace(), ))
line = line.replace($, $)
lines[i] = <br> + line
text = .join(lines)
return text
def _launch_demo(args, model, tokenizer):
uploaded_file_dir = os.environ.get(GRADIO_TEMP_DIR) or str(
Path(tempfile.gettempdir()) / gradio
)
def predict(_chatbot, task_history):
query = task_history[-1][0]
print(User: + _parse_text(query))
history_cp = copy.deepcopy(task_history)
full_response =
history_filter = []
audio_idx = 1
pre =
global last_audio
for i, (q, a) in enumerate(history_cp):
if isinstance(q, (tuple, list)):
last_audio = q[0]
q = fAudio {audio_idx}: <audio>{q[0]}</audio>
pre += q + \n
audio_idx += 1
else:
pre += q
history_filter.append((pre, a))
pre =
history, message = history_filter[:-1], history_filter[-1][0]
response, history = model.chat(tokenizer, message, history=history)
ts_pattern = r<\|\d{1,2}\.\d+\|>
all_time_stamps = re.findall(ts_pattern, response)
print(response)
if (len(all_time_stamps) > 0) and (len(all_time_stamps) % 2 ==0) and last_audio:
ts_float = [ float(t.replace(<|,).replace(|>,)) for t in all_time_stamps]
ts_float_pair = [ts_float[i:i + 2] for i in range(0,len(all_time_stamps),2)]
# 读取音频文件
format = os.path.splitext(last_audio)[-1].replace(.,)
audio_file = AudioSegment.from_file(last_audio, format=format)
chat_response_t = response.replace(<|, ).replace(|>, )
chat_response = chat_response_t
temp_dir = secrets.token_hex(20)
temp_dir = Path(uploaded_file_dir) / temp_dir
temp_dir.mkdir(exist_ok=True, parents=True)
# 截取音频文件
for pair in ts_float_pair:
audio_clip = audio_file[pair[0] * 1000: pair[1] * 1000]
# 保存音频文件
name = ftmp{secrets.token_hex(5)}.{format}
filename = temp_dir / name
audio_clip.export(filename, format=format)
_chatbot[-1] = (_parse_text(query), chat_response)
_chatbot.append((None, (str(filename),)))
else:
_chatbot[-1] = (_parse_text(query), response)
full_response = _parse_text(response)
task_history[-1] = (query, full_response)
print(Qwen-Audio-Chat: + _parse_text(full_response))
return _chatbot
def regenerate(_chatbot, task_history):
if not task_history:
return _chatbot
item = task_history[-1]
if item[1] is None:
return _chatbot
task_history[-1] = (item[0], None)
chatbot_item = _chatbot.pop(-1)
if chatbot_item[0] is None:
_chatbot[-1] = (_chatbot[-1][0], None)
else:
_chatbot.append((chatbot_item[0], None))
return predict(_chatbot, task_history)
def add_text(history, task_history, text):
history = history + [(_parse_text(text), None)]
task_history = task_history + [(text, None)]
return history, task_history,
def add_file(history, task_history, file):
history = history + [((file.name,), None)]
task_history = task_history + [((file.name,), None)]
return history, task_history
def add_mic(history, task_history, file):
if file is None:
return history, task_history
os.rename(file, file + .wav)
print(add_mic file:, file)
print(add_mic history:, history)
print(add_mic task_history:, task_history)
# history = history + [((file.name,), None)]
# task_history = task_history + [((file.name,), None)]
task_history = task_history + [((file + .wav,), None)]
history = history + [((file + .wav,), None)]
print(task_history, task_history)
return history, task_history
def reset_user_input():
return gr.update(value=)
def reset_state(task_history):
task_history.clear()
return []
with gr.Blocks() as demo:
gr.Markdown(\
<p align=center><img src=https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Audio/logo.jpg style=height: 80px/><p>) ## todo
gr.Markdown(<center><font size=8>Qwen-Audio-Chat Bot</center>)
gr.Markdown(
\
<center><font size=3>This WebUI is based on Qwen-Audio-Chat, developed by Alibaba Cloud. \
(本WebUI基于Qwen-Audio-Chat打造,实现聊天机器人功能。)</center>)
gr.Markdown(\
<center><font size=4>Qwen-Audio <a href=https://modelscope.cn/models/qwen/Qwen-Audio/summary>🤖 </a>
| <a href=https://huggingface.co/Qwen/Qwen-Audio>🤗</a>  |
Qwen-Audio-Chat <a href=https://modelscope.cn/models/qwen/Qwen-Audio-Chat/summary>🤖 </a> |
<a href=https://huggingface.co/Qwen/Qwen-Audio-Chat>🤗</a>  |
 <a href=https://github.com/QwenLM/Qwen-Audio>Github</a></center>)
chatbot = gr.Chatbot(label=Qwen-Audio-Chat, elem_classes=control-height, height=750)
query = gr.Textbox(lines=2, label=Input)
task_history = gr.State([])
mic = gr.Audio(source=microphone, type=filepath)
with gr.Row():
empty_bin = gr.Button(🧹 Clear History (清除历史))
submit_btn = gr.Button(🚀 Submit (发送))
regen_btn = gr.Button(🤔️ Regenerate (重试))
addfile_btn = gr.UploadButton(📁 Upload (上传文件), file_types=[audio])
mic.change(add_mic, [chatbot, task_history, mic], [chatbot, task_history])
submit_btn.click(add_text, [chatbot, task_history, query], [chatbot, task_history]).then(
predict, [chatbot, task_history], [chatbot], show_progress=True
)
submit_btn.click(reset_user_input, [], [query])
empty_bin.click(reset_state, [task_history], [chatbot], show_progress=True)
regen_btn.click(regenerate, [chatbot, task_history], [chatbot], show_progress=True)
addfile_btn.upload(add_file, [chatbot, task_history, addfile_btn], [chatbot, task_history], show_progress=True)
gr.Markdown(\
<font size=2>Note: This demo is governed by the original license of Qwen-Audio. \
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, \
including hate speech, violence, pornography, deception, etc. \
(注:本演示受Qwen-Audio的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,\
包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。))
demo.queue().launch(
share=args.share,
inbrowser=args.inbrowser,
server_port=args.server_port,
server_name=args.server_name,
file_directories=[/tmp/]
)
def main():
args = _get_args()
model, tokenizer = _load_model_tokenizer(args)
_launch_demo(args, model, tokenizer)
if __name__ == __main__:
main()
运行 demo
在终端中运行以下命令,启动streamlit服务
streamlit run /Qwen_Audio/compshared-tmp/chatBot.py --server.port 5910
#Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
# You can now view your Streamlit app in your browser.
# Local URL: http://localhost:5910
# Network URL: http://10.60.187.222:5910
# External URL: http://117.50.198.254:5910
点击这个外部链接http://117.50.198.254:5910让软件初始化激活,然后等待模型加载完毕后,在浏览器中打开链接 http://(外部IP):11434,即可看到聊天界面。

镜像信息
@敢敢のwings
已使用
11
镜像大小50GB
最近编辑2024-12-03
支持卡型
RTX40系48G RTX40系30902080
+4
框架版本
CUDA版本
12.4
应用
JupyterLab: 8888
版本
v1.0
2025-06-24

 扫码加入用户交流群
扫码加入用户交流群