Diffsinger 项目介绍
diffsinger仓库地址:https://github.com/openvpi/DiffSinger/tree/multi-dict
数据集工具仓库地址:https://github.com/BaiShuoQwQ/diffsinger_dataset_tools
文档地址:https://ecn4x4y9jhjs.feishu.cn/wiki/UK6xwL37NivMfDk8PnnckZGUngZ
镜像作者:bilibili@kiss丿冷鸟鸟
UP的交流群:829974025
注意:请在获取干声前确保你的数据来源合法合规!!!
请遵守相关法律法规使用该镜像
由使用者违规使用造成的后果全部由使用者承担,与镜像作者,模型作者,以及算力平台无任何关系
镜像使用多词典分支,支持跨语种(默认中日)
更新日志 2025/1/14
- 上传该镜像
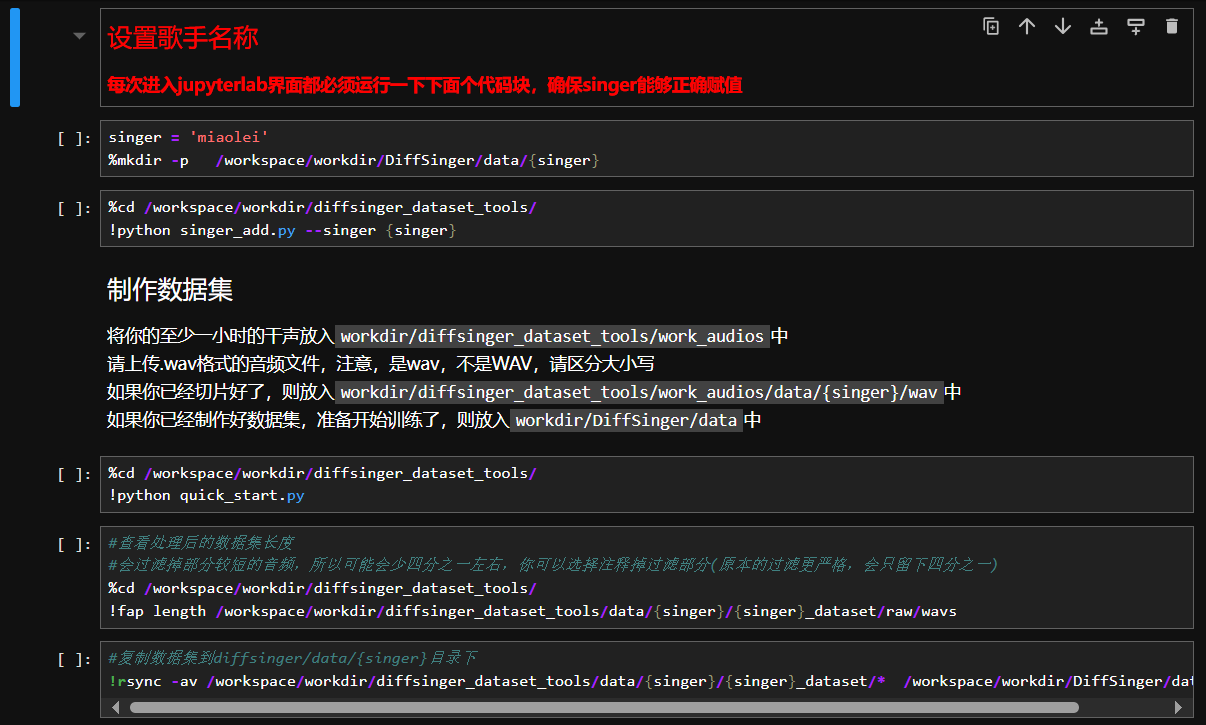
关于数据集(干声获取)
请使用已授权的音频进行训练
对于UVR或者MSST处理得到的干声,不推荐作为数据集使用
镜像内全自动数据集制作目前只支持中文
diffsinger对于数据集的要求很高,最好是录音棚使用较为专业的设备录制的音频
音频时长至少1小时以上,16kHz以下频段完整,存为单声道wav格式,至少16bit位深
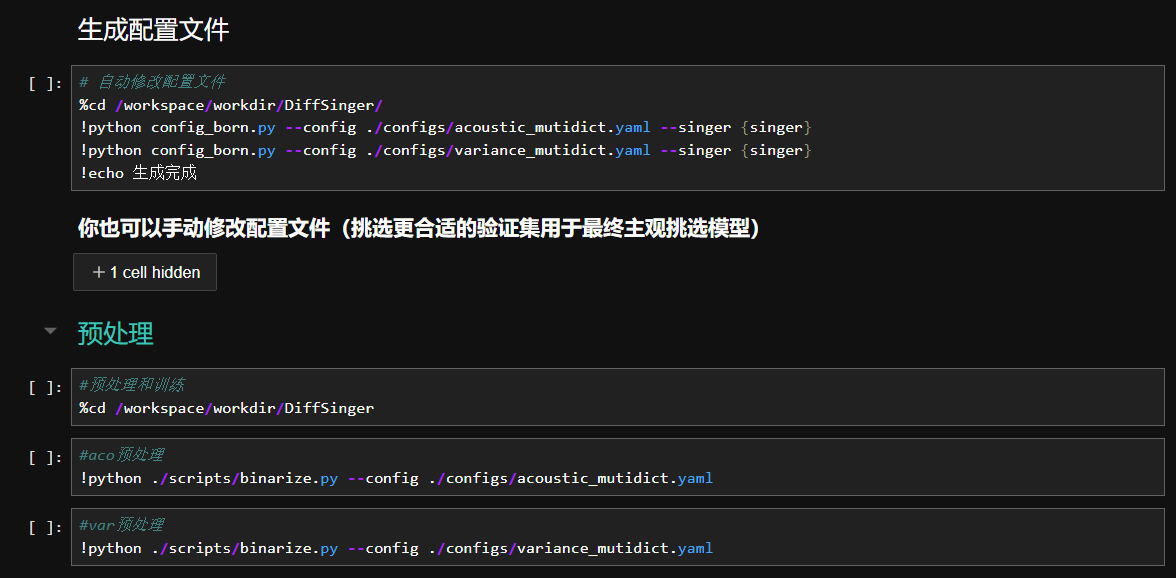
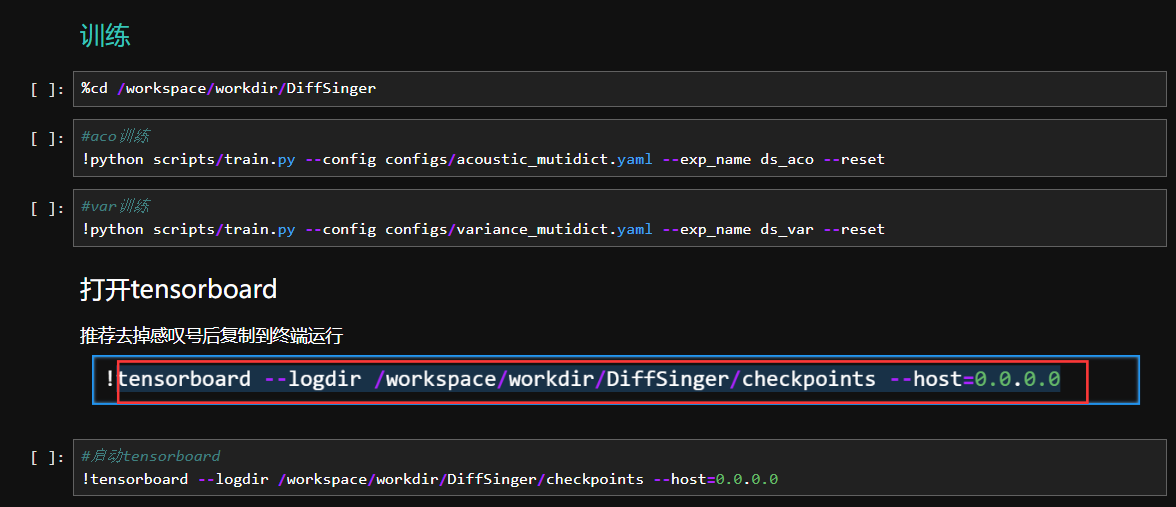
关于训练
除了改配置文件基本都是全自动了,如果你想自己修改参数的话,请查看文档
https://ecn4x4y9jhjs.feishu.cn/wiki/UK6xwL37NivMfDk8PnnckZGUngZ
训练时间,大概一天或者半天就够了
一些说明
用于训练的数据集存放于Diffsinger/data中,默认的itako,karasu,opencpop为带练数据,用于跨语种和保证你的音素能够覆盖字典,剩下的{singer}为你的,已经处理好的数据
在修改配置文件后,需要重新预处理
预处理后的数据位于Diffsinger/data中,默认为ds_aco和ds_var
训练好的模型可在Diffsinger/checkpoints_viewer中查看
转换后的onnx模型在Diffsinger/*_ONNX中(最终用于打包成声库)
镜像并未开启自动音高,如过你觉得你的数据还不错,则将variance_mutidict.yaml中的predict_pitch改为True
配置文件自动生成,包括验证集,如果你想自己挑选验证集,那就自己去改
因为是全自动,所以效果可能会打点折,如果你觉得效果不太好请自行手动标注或者找人精标
之后可能会拆分一下标注步骤,手动校准,半自动效果可以参考BV1XD4y177NY
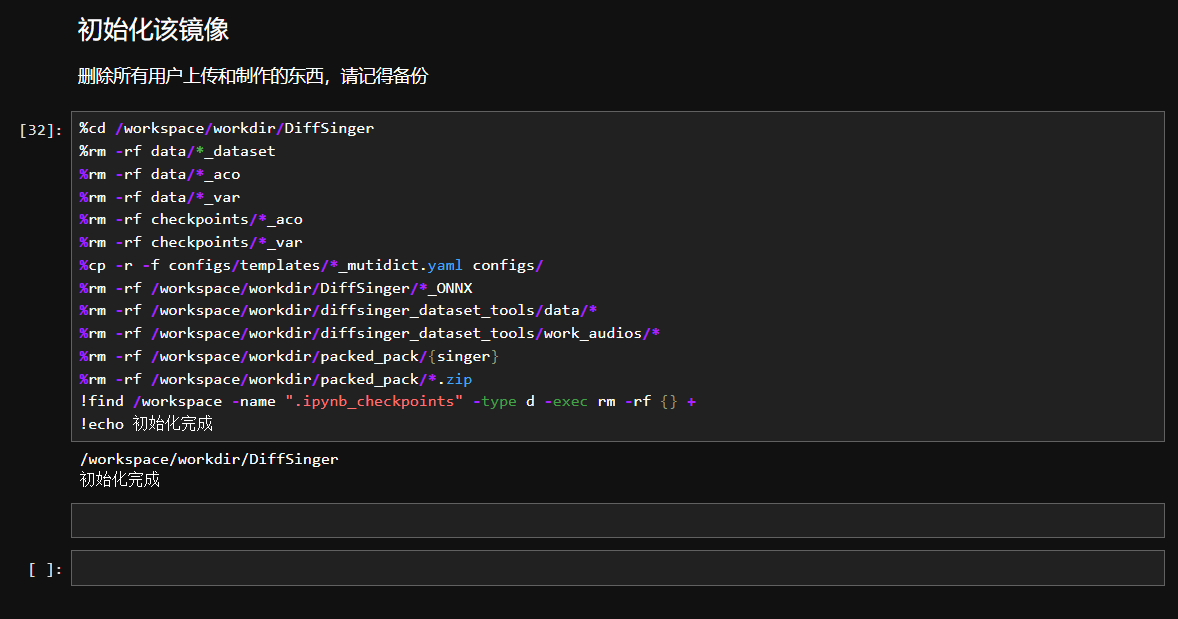
使用教程可参考JupyterLab中的“数据集处理和训练.ipynb”这个文件的内容



 扫码加入用户交流群
扫码加入用户交流群