语音
WebUI
CosyVoice
阿里 TTS模型,提供多语言语音生成、零样本语音生成、跨语言语音克隆和指令跟随能力
0元/小时
v1.0
CosyVoice 镜像使用指南
镜像作者:bilibili@爱过_留过
交流群:172701496
项目地址: https://github.com/FunAudioLLM/CosyVoice
aiguoliuguo-镜像作者交流群

CosyVoice 1.0 主要特性
- 多语言支持: 中文、英文、日语、韩语、中文方言 (粤语、四川话、上海话、天津话、武汉话等)。
- 跨语言 & 混合语言: 支持跨语言和代码切换场景下的零样本语音克隆。
- 可以查看论文, 模型, 以及示例: CosyVoice 1.0
使用步骤
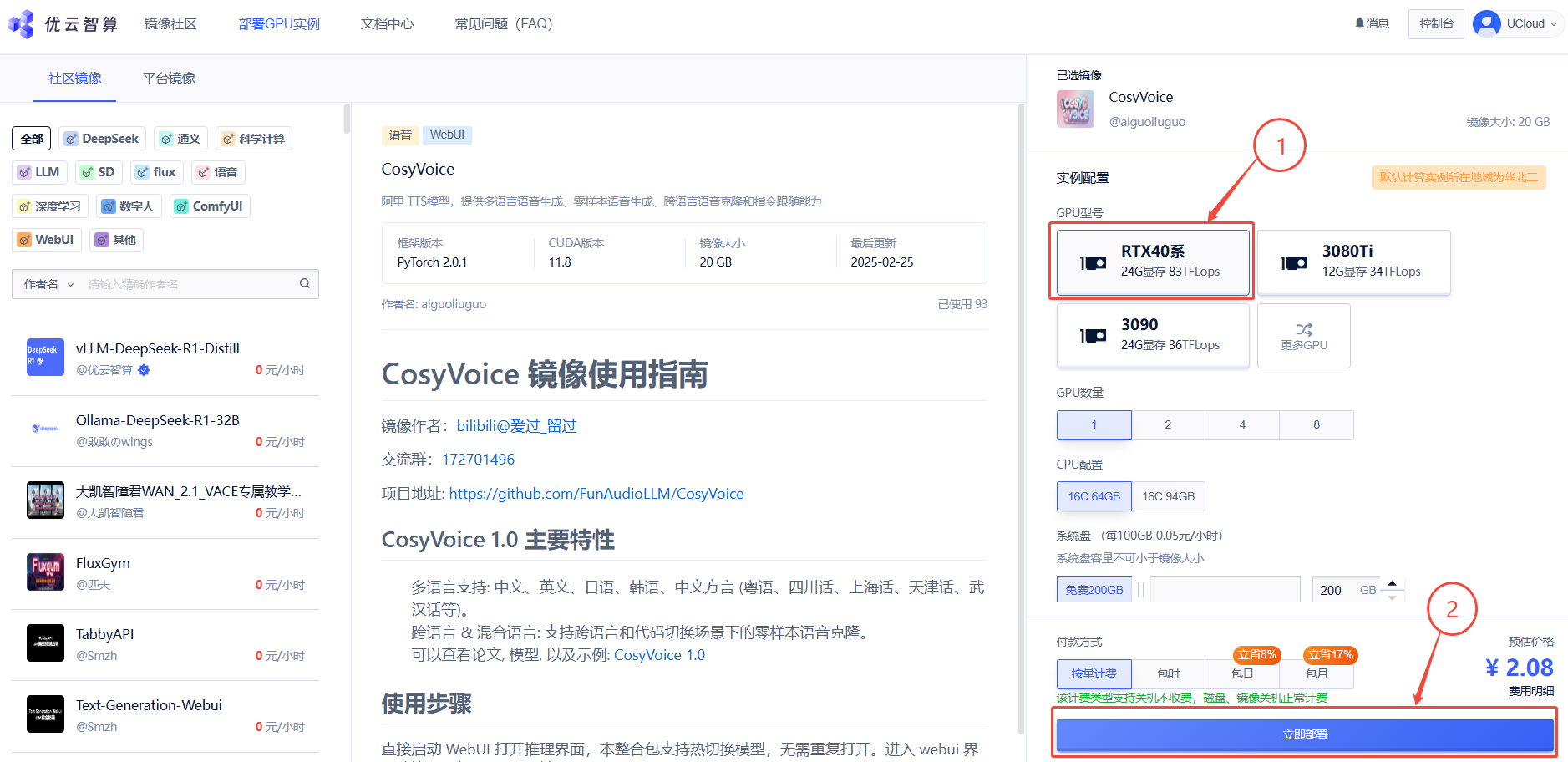
1. 先选择卡型,再点击“立即部署”
2. 待实例创建完成后,在控制台-应用打开“JupyterLab”

3. 进入JupyterLab后,选择“quick_setup.ipynb”进入,选择“启动webui”板块,点击运行
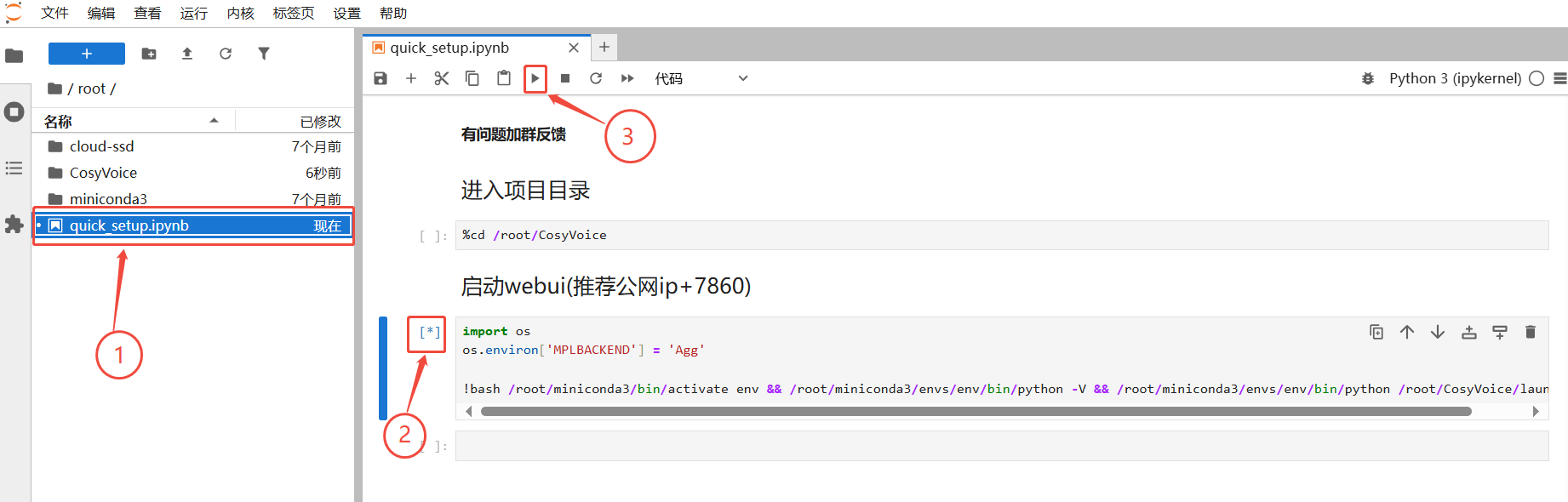
4. 运行后,在浏览器中输入 ip:7860 进入web界面,ip可以在控制台-基础网络(外)获取,如图所示,ip为117.50.196.171

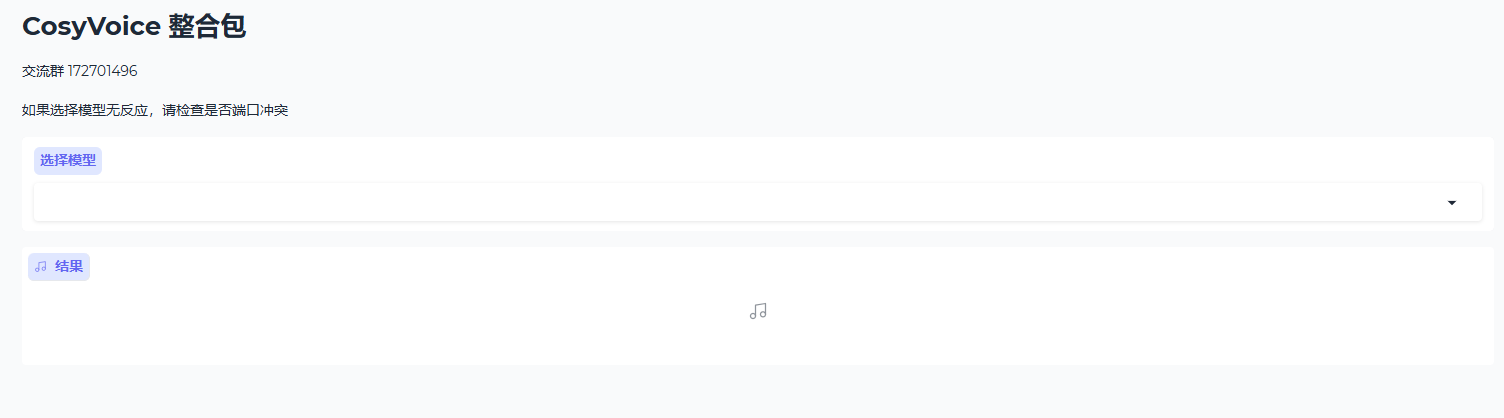
5. 成功启动后进入web界面如下图所示

镜像信息
@aiguoliuguo
已使用
106
镜像大小20GB
最近编辑2025-02-10
支持卡型
RTX40系48G RTX40系P4030903080Ti2080
+6
框架版本
CUDA版本
11.8
应用
JupyterLab: 8888
版本
v1.0
2025-07-02

 扫码加入用户交流群
扫码加入用户交流群