MOSS-TTSD邱锡鹏团队开源最新百万小时训练声音推理模型声音克隆 构建By科哥
MOSS-TTSD邱锡鹏团队开源最新百万小时训练声音推理模型声音克隆 构建By科哥
 3
30元/小时
v1.0
MOSS-TTSD 声音推理模型&声音克隆镜像使用教程
镜像简介
本镜像基于邱锡鹏团队开源的MOSS-TTSD最新语音模型,该模型经过百万小时大规模训练,具备高质量的声音推理、合成与克隆能力。用户可通过少量音频样本快速复刻音色,生成自然流畅的个性化语音。适用于虚拟助手、有声内容创作及个性化语音服务等场景,提供开箱即用、完全免费的本地化语音AI解决方案。
镜像使用指南
已经设置开机运行
1.创建实例
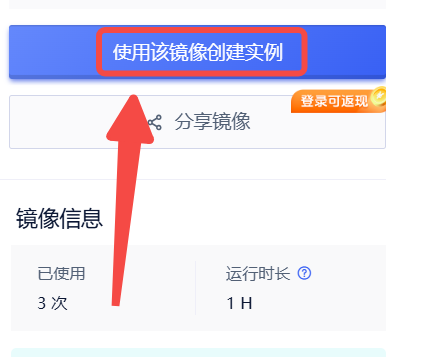
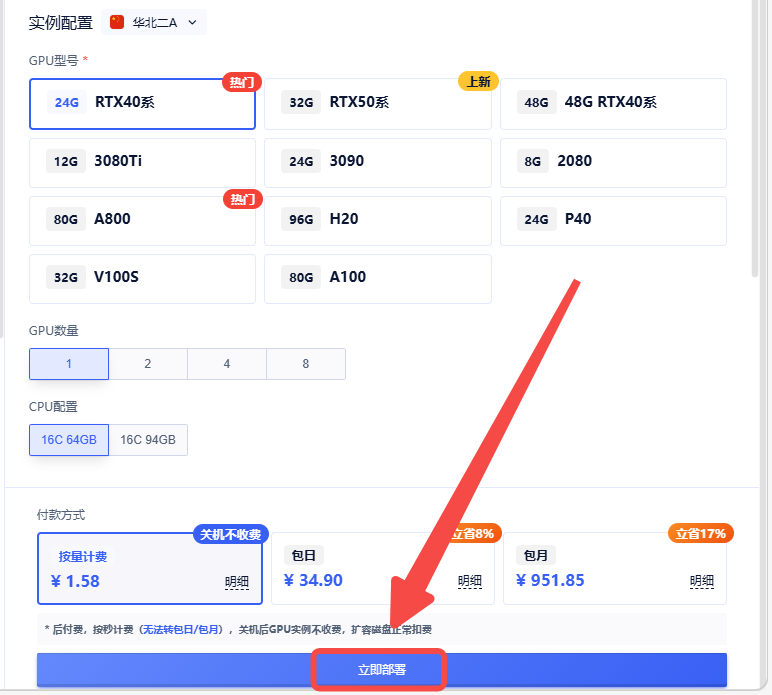
2.选择合适的机型,立即部署
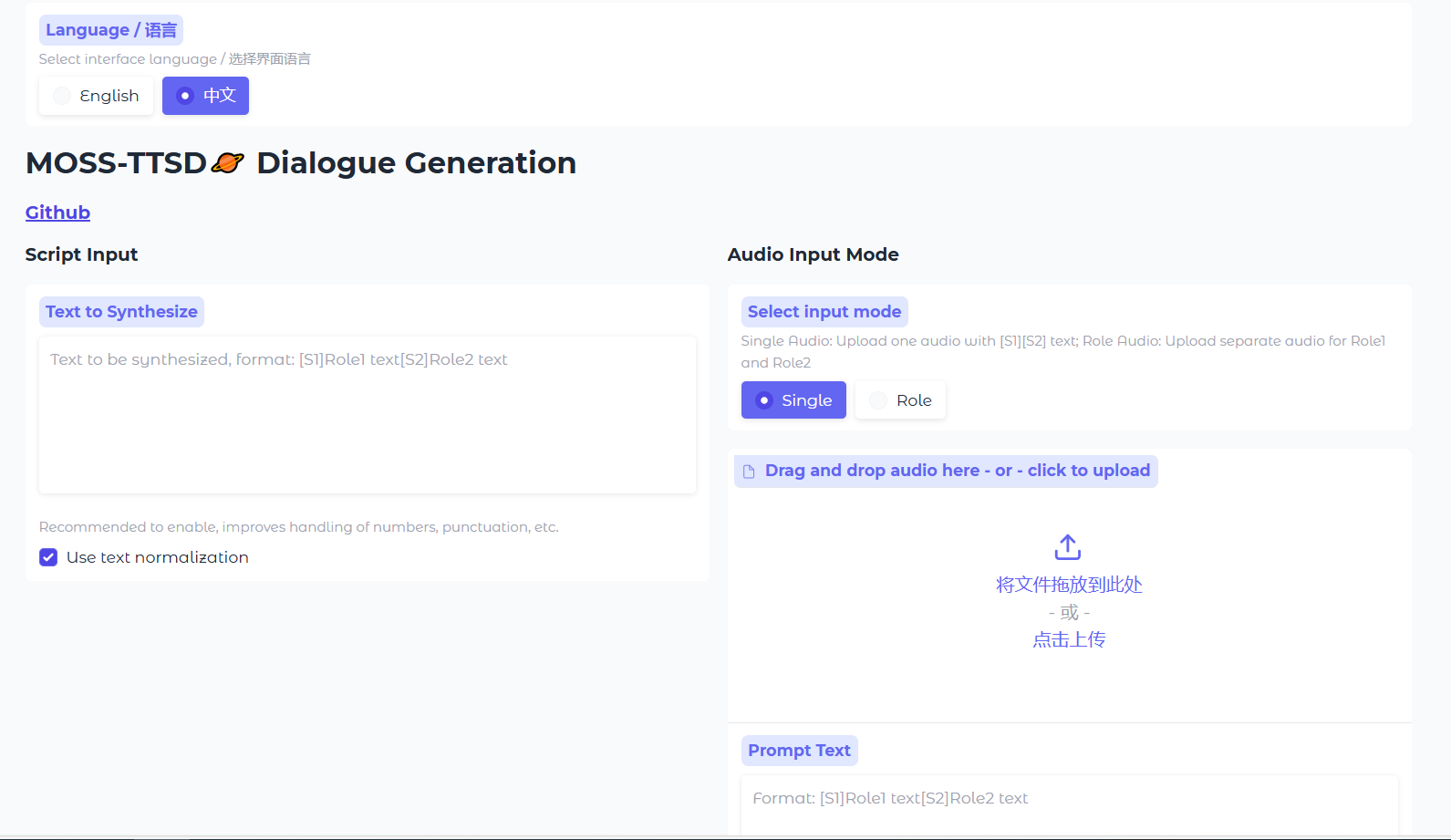
3.打开控制面板的【webui】即可进入使用界面;
4.如果没有正常运行,请打开jupyterlab页面,进入终端,输入:
cd /root && bash run.sh
回车执行,等待类似:http://0.0.0.0:7860 出现,再返回控制台,打开webUI即可进入操作页面。
官方更新源码在这里:https://github.com/OpenMOSS/MOSS-TTSD
注意:因为项目使用到FlashAttention 加速技术,项目只能在NVIDIA 的 RTX 30 系列及以上的显卡机器上面运行。
- 有bug请微信科哥: 312088415
-
bug反馈可以加入科哥专属群交流!

@鸡你太美 认证作者
认证作者
认证作者

镜像信息
已使用75 次
运行时长
86 H
 支持自启动
支持自启动镜像大小
50GB
最后更新时间
2026-04-27
支持卡型
RTX40系20803080Ti309048G RTX40系2080TiH20A800P40A100RTX50系V100SV100S
+13
框架版本
CUDA版本
12.1
应用
JupyterLab: 8888
版本
v1.0
2026-04-27